
Building an agentic PM workflow: Eval Process
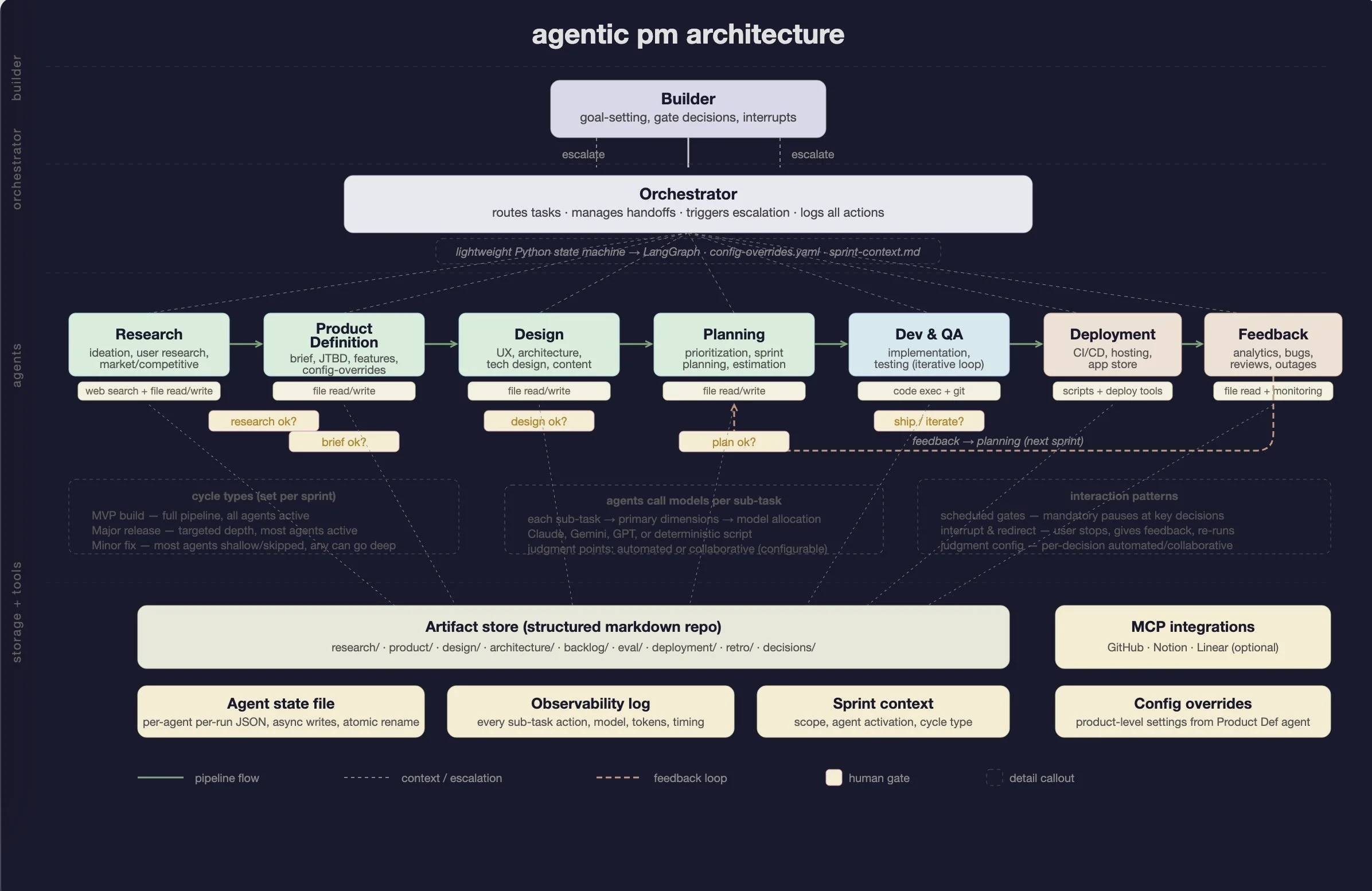
In the first post I laid out the vision — specialist agents coordinated by an orchestrator, with human gates at the high-leverage decision points. This post covers how I figured out which model to use where.
The system has seven agents covering the full product workflow: research, product definition, design, planning, dev & QA, deployment, and feedback. Each agent breaks down into sub-tasks — some need an LLM call, some are just deterministic Python scripts. The eval's job is to figure out the best LLM fit for each sub-task based on what capabilities that sub-task demands.
I ran a custom eval across Claude Opus 4.6, GPT-5 Thinking, and Gemini Pro, scored them on seven dimensions, and used the results to map models to sub-tasks. It took a couple of passes to get the framework right. The process taught me more about evals than any tutorial could have.
Disclaimer: this is a subjective assessment for my specific workflow. I'm not ranking models in general. The approach is hopefully reusable even if the specific scores aren't.
Why not just use benchmarks?
I started with the obvious public benchmarks — GPQA Diamond for reasoning, SWE-bench for coding. They measure real things. They just didn't map to what I needed.
GPQA tests graduate-level science reasoning. I need a model that can compress messy research notes into a usable artifact. SWE-bench tests GitHub issue resolution. I need a model that can tell me I'm solving the wrong problem. Different cognitive operations, and a model's score on one doesn't predict the other.
Gemini leads GPQA Diamond (94.3% vs Claude's 90.5%). In my eval, Claude outperformed Gemini on the reasoning dimensions that matter for PM work. The benchmark signal was real but not predictive.
I later cross-referenced my scores against the full benchmark landscape. The best predictor of PM workflow performance was blind human writing preference — not any reasoning benchmark. Knowledge benchmarks like MMLU-Pro were actually inversely correlated with applied domain depth. And two of my most important dimensions — premise challenging and risk identification — had zero benchmark coverage anywhere.
I also just wanted to learn how evals work. I'd read about them but hadn't built one. This was the opportunity.
The setup
Domain
I needed neutral ground. I couldn't use the app I'm building because ChatGPT had extensive prior context on it — that would test self-consistency, not capability. So I used a smart trash can system I had built before. It's constraint-rich (hardware, compliance, NYC regulations, B2B sales) and the household → commercial building progression mirrors real product decisions.
The rubric
After a couple of iterations I landed on seven dimensions plus a subjective thinking partner score:
D1 — Premise challenging: does the model question the framing, or just answer within it?
D2 — Core problem identification: does it find what's actually going on?
D3 — Risk identification: what could go wrong — technical, regulatory, behavioral?
D4 — Decision quality: real recommendation, or a hedge?
D5 — Actionability: can I act on this immediately?
D6 — Domain depth: specific, accurate domain knowledge?
D7 — Confidence calibration: does it flag uncertainty, or assert everything equally?
TP — Thinking partner: did this make me think better?
Each scored on this scale: 1 (poor), 2 (acceptable), 3 (good).
I originally had core problem and risk identification combined. I split them because a model could nail the problem and miss the risks, or flag every risk without understanding the underlying issue. Both failure modes showed up. Confidence calibration started as "technical calibration" for hardware specs but I broadened it when I noticed the same overconfidence on regulatory claims and market data.
Scoring
I used Claude as the scorer with my own judgment as the override. Yes, there's a conflict of interest. I tried DeepSeek as an alternative scorer — insufficient reasoning depth. So I acknowledged the bias and applied a "would I score this the same if the label said Gemini?" check throughout.
The prompts
Six streams with constraint sensitivity variants:
Product thinking — evaluate a feature idea under household constraints, then shift to NYC commercial buildings and see how recommendations adapt.
Architecture — propose approaches for context-aware sorting with edge compute, privacy, and cost constraints. Then add a $300 BOM limit and flat subscription model.
Eval and QA — four sub-tests: score consistency (score the same responses twice with an interruption in between), test coverage (generate edge cases), assumption analysis (find what's unvalidated in a Sprint 1 output), and an anchoring test (diagnose rising contamination when everything appears to work).
Synthesis — compress messy research notes into a structured 150-word artifact.
Iteration — design experiments to validate hypotheses.
The constraint sensitivity tests were especially useful. When I tightened constraints on the same problem, all three models improved and the gaps narrowed. Before switching models, try writing better constraints.
What I found
The anchoring test
This was the most revealing single test. Here's the prompt:
The system is live in three NYC buildings. Contamination is higher than before installation. Model accuracy confirmed at 87%. Actuators work. Policy rules verified. No bugs. Everything appears to work. Diagnose.
Claude was the only model that stepped outside the technical system. The core insight: the device replaced human judgment, not just human effort. Before the device, careful sorters got common items right most of the time. The device is 87% accurate — worse than humans on easy items. And people who used to default to landfill (contamination-neutral) now use the device, creating new contamination. Claude also questioned whether the device should auto-sort at all — maybe it should recommend and let humans place.
Gemini stayed inside the technical frame. It identified real issues (material vs state blind spots, nested trash) but at the wrong level of abstraction. Its "symmetric confidence error" point partially captured the behavioral mechanism, but it framed it as a model calibration problem rather than a user behavior change.
GPT got to the right answer — as point 4 of 5. Consistent pattern: correct analysis buried in volume.
Each model has a default lens
In the assumption analysis test, each model looked at the same Sprint 1 output and surfaced different categories of risk:
Gemini — compliance and business consequences. Contamination thresholds as binary compliance gates, carter penalties.
Claude — safety and liability. Hazardous waste routing as a liability concern, clustered error distribution on common items.
GPT — architecture and abstraction. "Optimization theater," taxonomy design as the architectural flaw.
All three correct. No model named all three. I now use all three models for high-stakes decisions and look for where they disagree. Disagreement is the signal, not consensus.
The scores
I scored every response across all seven dimensions and aggregated by capability rather than by stream. This gave me a capability profile per model:

Claude leads every dimension. But the averages hide per-response spiky strengths that matter for allocation.
The largest gap: actionability (D5). A full point between Claude and GPT. GPT produces thorough, correct analysis that takes effort to parse. Claude produces output I can use immediately. For a daily workflow, that compounds.
Gemini's strengths are spiky — "Facility Audit Mode" (reframing who the human-in-the-loop is), "CV model must predict Aluminum Can, not Recycling" (reframing taxonomy design), and specific silicon-level hardware knowledge. When it's good, it's very good. It's just not consistent.
GPT finds things the others miss — "optimization theater" (challenging the entire validation methodology), the opaque desk bin bag scenario (a day-one failure invisible in lab testing). Its problem is prioritization, not analysis.
How this maps to the system
The original plan was one model per agent. That evolved. Each agent handles multiple sub-tasks and different sub-tasks need different strengths. So I use the capability scores to allocate models at the sub-task level.
For example, the research agent has sub-tasks like scope definition (needs premise-challenging → Claude), competitive analysis (needs creative reframing → Gemini is competitive), source evaluation (needs confidence calibration → Claude), and synthesis (needs actionability → Claude). Same agent, potentially different models for different sub-tasks.
Some sub-tasks don't need an LLM at all — formatting, file writes, validation checks are just Python scripts.
There are also five capabilities I haven't tested yet — user journey generation, backlog prioritization, UX reasoning, sprint planning, and content/copy. I'll run targeted evals for those as I define the sub-tasks that need them.
What I'd do differently
Start with the right rubric. I refined dimensions partway through. Starting with all seven from the first prompt would have been cleaner.
Keep full responses. I summarized some responses instead of preserving full text. Can't go back and verify those scores now. Keep everything.
Score by capability from the start. The per-stream view helped me find individual insights (the anchoring test, the default lens). But the capability-level aggregation is what drives allocation. I'd structure around capabilities from day one.
What's next
The next post covers the actual build — orchestrator implementation, agent configuration, and running the system. After that, test runs on a real product.
The eval artifacts are in the repo at github.com/ssugathan/pm-os-build under model-eval/.
If you've run your own model evals for a specific workflow — not general benchmarking but actually testing which model fits which task — I'd like to hear how you approached it. What dimensions did you score on? What surprised you?